MAP parameter estimation for an LG-SSM using EM and SGD#
This notebook shows how to “fit” a linear Gaussian SSM — i.e., estimate the parameters and infer the latent states — using either expectation-maximization (EM) or stochastic gradient descent (SGD) on the negative log marginal likelihood of the data.
Here, we work with simulate noisy data from an LG-SSM with known parameters, and then we see how well we can recover the true parameters and states given the observations. The model is,
where \(z_{1:T}\) are the latent states, \(y_{1:T}\) are the emissions, and \(\theta = (F, Q, H, R)\) are the model parameters. In particular, \(F\) is the dynamics matrix and \(H\) is the emission matrix. For our simulation, we use 2-dimensional latent states, \(z_t \in \mathbb{R}^2\), and 10-dimensional emissions, \(y_t \in \mathbb{R}^10\).
We fit the model to estimate parameters, \(\hat{\theta}\), using either EM or SGD, as shown below. Once we have estimated the paraemeters, we can also infer the latent states given those parameters.
Setup#
import jax.numpy as jnp
import jax.random as jr
from jax import vmap
from matplotlib import pyplot as plt
from optax import adam
from dynamax.linear_gaussian_ssm import LinearGaussianSSM
from dynamax.utils.utils import monotonically_increasing, random_rotation
Data#
Simulate 2-dimensional latent states and 10-dimensional emissions from a linear Gaussian SSM with randomly initialized parameters. By default, initialize sets the dynamics matrix to \(F = 0.99 I\) so that the dynamics are a stable, slowly decaying random walk.
state_dim = 2
emission_dim = 10
num_timesteps = 100
k1, k2, k3 = jr.split(jr.PRNGKey(0), 3)
# Construct the true model with randomly initialized parameters
true_A = 0.99 * random_rotation(seed=k1, n=state_dim, theta=jnp.pi / 10)
true_Sigma = 0.01 * jnp.eye(state_dim)
true_model = LinearGaussianSSM(state_dim, emission_dim)
true_params, param_props = true_model.initialize(
key=k1, dynamics_weights=true_A, dynamics_covariance=true_Sigma)
# Sample states and emissions from the true model
true_states, emissions = true_model.sample(true_params, k3, num_timesteps)
Visualizing the emissions and model forecasts.#
Before fitting a model, we show how you can use a model to smooth the noisy observations and forecast future emissions.
Given noisy emissions, \(y_{1:T}\), and parameters, \(\theta\), we can compute the posterior mean of the latent states,
using a Kalman smoother. (The model.smoother function returns the posterior distribution over latent states.) We can also reconstruct the emissions by passing the posterior mean over states through the emission distribution to obtain,
Similarly, we can compute the covariance of the reconstruction as,
where \(\epsilon_t \sim \mathrm{N}(0, R)\) is the emission noise and \(\Sigma_{t|T} = \mathbb{V}[z_t \mid y_{1:T}; \theta]\) is the posterior marginal covariance.
These quantities are computed by the model.posterior_predictive function, as illustrated below. Note that the term posterior predictive distribution can be ambiguous. Here we refer to the predictive distribution of current emissions \(y_{1:T}\) under the posterior distribution \(p(z_{1:T} \mid y_{1:T}; \theta)\).
Another type of posterior prediction is over future latent states and emissions. The model.forecast function computes these predictions over a specified time horizon. The plots below show the forecasted future emissions based on the given model parameters and the observations up to time \(T\).
def plot_emissions_and_forecast(model, params, emissions,
num_forecast_timesteps=50,
spc=4):
"""
Plot the true emissions, the reconstructed emissions, and the future forecast.
"""
num_timesteps = emissions.shape[0]
t_obs = jnp.arange(num_timesteps)
t_forecast = jnp.arange(num_timesteps, num_timesteps + num_forecast_timesteps)
recon_emissions, recon_emissions_std = model.posterior_predictive(params, emissions)
_, _, forecast_emissions, forecast_emissions_cov = model.forecast(params, emissions, num_forecast_timesteps)
forecast_emissions_std = jnp.sqrt(vmap(jnp.diag)(forecast_emissions_cov))
for i in range(emission_dim):
# Plot the emissions
# axs[1].axhline(i *spc, color="black", linestyle=":", alpha=0.5)
plt.plot(emissions[:, i] + spc * i, "--k", label="observed" if i == 0 else None)
ln = plt.plot(t_obs, recon_emissions[:, i] + spc * i,
label="smoothed" if i == 0 else None)[0]
plt.fill_between(
t_obs,
spc * i + recon_emissions[:, i] - 2 * recon_emissions_std[:, i],
spc * i + recon_emissions[:, i] + 2 * recon_emissions_std[:, i],
color=ln.get_color(),
alpha=0.25,
)
# Plot the forecast
plt.plot(t_forecast, forecast_emissions[:, i] + spc * i,
ls=':', c=ln.get_color(), label="forecast" if i == 0 else None)[0]
plt.fill_between(
t_forecast,
spc * i + forecast_emissions[:, i] - 2 * forecast_emissions_std[:, i],
spc * i + forecast_emissions[:, i] + 2 * forecast_emissions_std[:, i],
color=ln.get_color(),
alpha=0.25,
)
# Draw a dividing line between observations and forecasts
plt.axvline(num_timesteps, color="black", linestyle="-", lw=2)
# Label the axes
plt.xlabel("time")
plt.xlim(0, num_timesteps + num_forecast_timesteps - 1)
plt.ylabel("emissions")
plt.yticks(spc * jnp.arange(emission_dim),
[f"dim. {i}" for i in jnp.arange(emission_dim)])
plt.legend()
plt.grid(True)
plt.tight_layout()
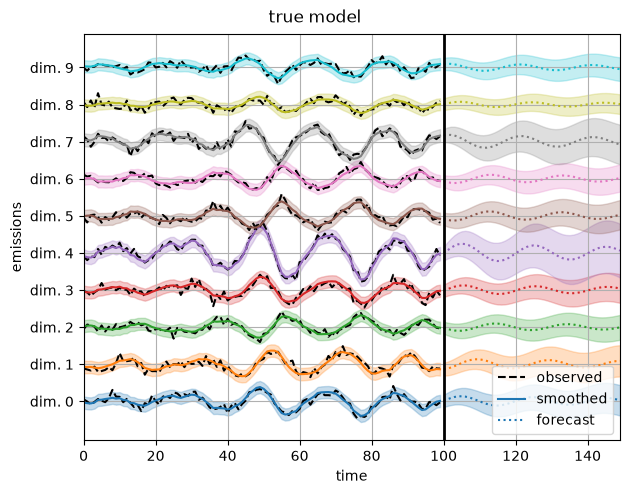
First, plot the reconstructions under the true model.
# plot_states_and_emissions(true_model, true_params, emissions)
plot_emissions_and_forecast(true_model, true_params, emissions)
plt.suptitle("true model", y=1.02)
Text(0.5, 1.02, 'true model')
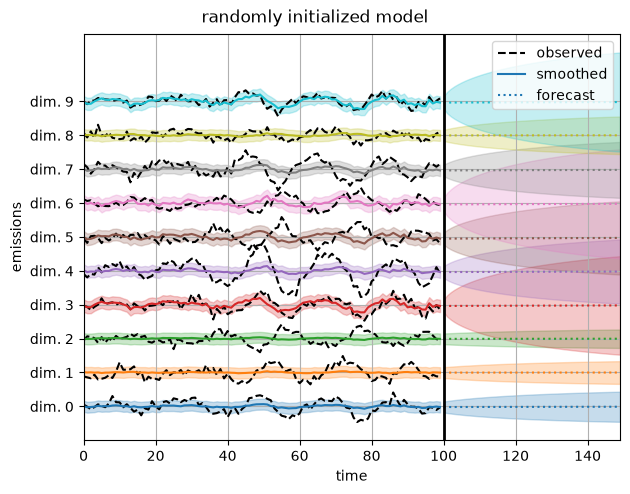
Now plot the reconstructions under a randomly initialized model. They’re much worse!
# Plot predictions from a random, untrained model
init_key = jr.PRNGKey(42)
model = LinearGaussianSSM(state_dim, emission_dim)
params, param_props = model.initialize(init_key)
plot_emissions_and_forecast(model, params, emissions)
plt.suptitle("randomly initialized model", y=1.02)
Text(0.5, 1.02, 'randomly initialized model')
Fit with EM#
Let’s fit the model to the data using expectation-maximization (EM) algorithm. As with hidden Markov models, EM alternates between inferring the latent states (E-step) and then maximizing the expected log probability of the states and emissions (M-step). The E-step is implemented with a Kalman smoother. The M-step has a closed form solution for linear Gaussian state space models, so the algorithm is very efficient!
params, marginal_lls = model.fit_em(params, param_props, emissions, num_iters=100)
assert monotonically_increasing(marginal_lls, atol=1e-2, rtol=1e-2)
We zoom in on the learning curve after the first iteration since the first log likelihood is much lower than the rest.
true_ll = true_model.marginal_log_prob(true_params, emissions)
plt.axhline(true_ll, color = 'k', linestyle = '--', lw=2, label="true")
plt.plot(marginal_lls, '-', ms=4, label="estimated")
plt.xlabel("iteration")
plt.ylabel("marginal log likelihood")
plt.ylim(marginal_lls[1] - 25, marginal_lls[-1] + 25)
plt.legend()
plt.tight_layout()
plt.grid(True)
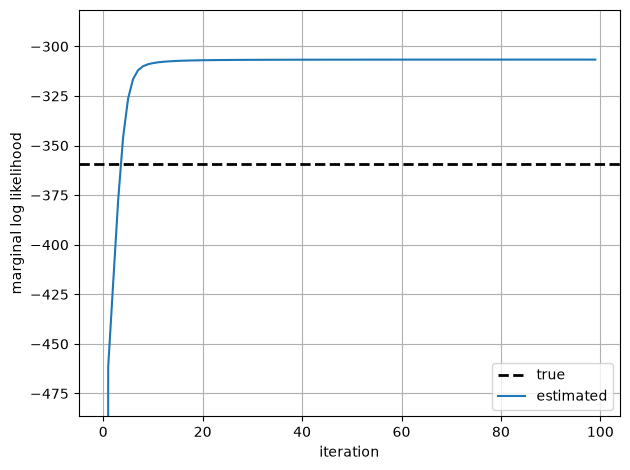
The marginal log likelihood quickly converges. As with the HMM examples, the likelihood under the estimated parameters is larger than the likelihood under the true parameters that generated the data. This isn’t surprising: EM is finding the parameters \(\hat{\theta}_{\mathsf{MLE}}\), that maximize the likelihood, and with a short sequence like this, the likelihood \(p(x_{1:T}; \hat{\theta}_{\mathsf{MLE}})\) is almost surely larger than \(p(x_{1:T}; \theta_{\mathsf{true}})\).
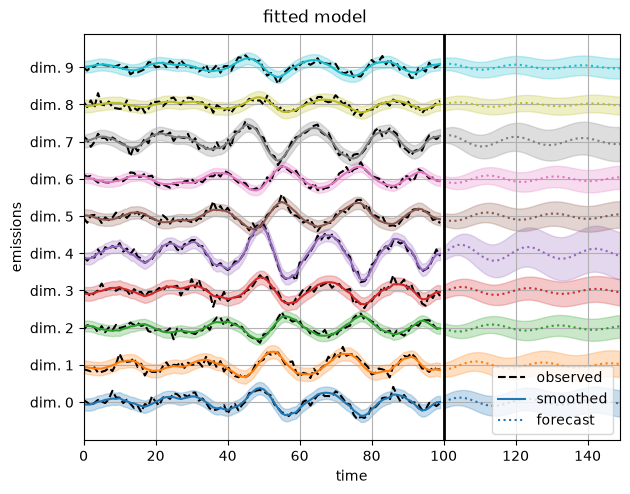
Last but not least, reconstructing the data with the estimated parameters yields nice predictions.
plot_emissions_and_forecast(model, params, emissions)
plt.suptitle("fitted model", y=1.02)
Text(0.5, 1.02, 'fitted model')
Identifiability#
Notice how the fitted model is able to reconstruct the emissions, but the inferred latent states do not match the true latent states. That’s because the latent state are only identifiable up to an orthogonal transformation. We can always map \(z_t \mapsto A z_t\) where \(A\) is an orthogonal matrix, and then account for the transformation with a commensurate change in the parameters.
Fit with SGD#
As with HMMs, we can also fit the model parameters by using (stochastic) gradient descent on the negative marginal log likelihood. You can use an optimizer of your choice, like Adam. You’ll have to explore various learning rates (and possibly other hyperparameters as well). We recommend that you start with EM since it tends to converge more quickly, but currently SGD supports some features that EM doesn’t. For example, SGD allows you to fix certain parameters during training.
sgd_key = jr.PRNGKey(1234)
learning_rates = [1e-2, 1e-1, 2.5e-1]
all_sgd_params = []
all_sgd_marginal_lls = []
for lr in learning_rates:
print(f"fitting with Adam and learning rate {lr}")
optimizer = adam(learning_rate=lr)
sgd_params, sgd_param_props = model.initialize(init_key)
sgd_params, losses = model.fit_sgd(sgd_params,
sgd_param_props,
emissions,
num_epochs=1000,
optimizer=optimizer,
key=sgd_key)
sgd_marginal_lls = -losses * emissions.size
all_sgd_marginal_lls.append(sgd_marginal_lls)
all_sgd_params.append(params)
fitting with Adam and learning rate 0.01
fitting with Adam and learning rate 0.1
fitting with Adam and learning rate 0.25
# Plot the SGD learning curves and the true LL for comparison
true_ll = true_model.marginal_log_prob(true_params, emissions)
plt.axhline(true_ll, color = 'k', linestyle = '--', lw=2, label="true")
for lr, lls in zip(learning_rates, all_sgd_marginal_lls):
plt.plot(lls, '-', ms=4, label=f"lr={lr}")
plt.xlabel("epochs")
plt.ylabel("marginal log likelihood")
plt.ylim(true_ll - 3000, true_ll + 100)
plt.legend()
plt.tight_layout()
plt.grid(True)
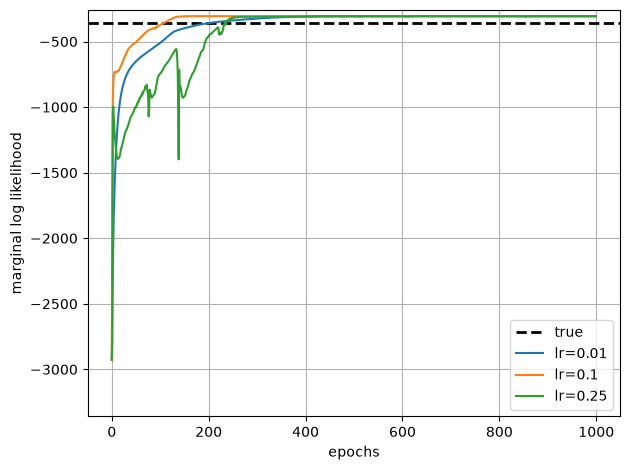
Adam eventually converges, but note that both the y-axis and x-axis scales are much larger than for EM. It takes 100s of epochs to achieve comparable log likelihoods, and each epoch is roughly the equivalent cost to one iteration of EM.
Freezing parameters#
Now let’s fit an LG-SSM with certain parameters held fixed. For example, the code below freezes the dynamics to the true values.
sgd_key = jr.PRNGKey(1234)
init_key = jr.PRNGKey(42)
optimizer = adam(learning_rate=1e-2)
sgd_params, sgd_param_props = model.initialize(
init_key, dynamics_weights=true_A, dynamics_covariance=true_Sigma)
print(f"freeing the dynamics matrix to:\n {sgd_params.dynamics.weights}")
sgd_param_props.dynamics.weights.trainable = False
sgd_param_props.dynamics.cov.trainable = False
# Fit the model with SGD
sgd_params, losses = model.fit_sgd(sgd_params,
sgd_param_props,
emissions,
num_epochs=1000,
optimizer=optimizer,
key=sgd_key)
sgd_marginal_lls = -losses * emissions.size
# Check that the dynamics matrix has not been updated
print(f"dynamics matrix after fitting:\n {sgd_params.dynamics.weights}")
assert jnp.allclose(sgd_params.dynamics.weights, true_A)
freeing the dynamics matrix to:
[[ 0.9415461 0.30592695]
[-0.30592677 0.9415459 ]]
dynamics matrix after fitting:
[[ 0.9415461 0.30592695]
[-0.30592677 0.9415459 ]]
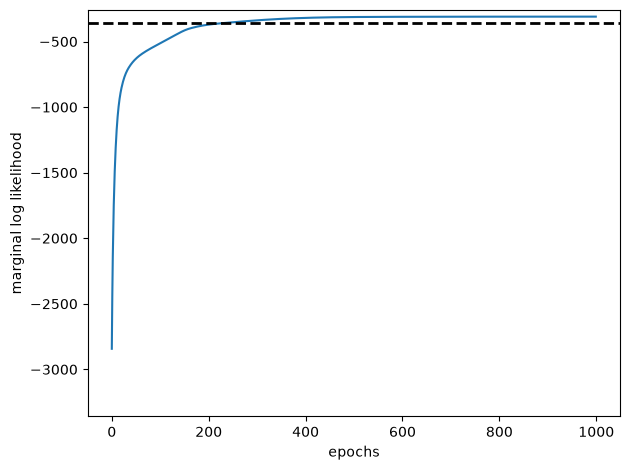
# Plot the SGD learning curve and the true LL for comparison
plt.plot(sgd_marginal_lls, '-', ms=4, label="estimated")
plt.axhline(true_ll, color = 'k', linestyle = '--', lw=2, label="true")
plt.xlabel("epochs")
plt.ylabel("marginal log likelihood")
plt.ylim(true_ll - 3000, true_ll + 100)
plt.tight_layout()
Conclusion#
This notebook shows how to fit linear Gaussian state space models (i.e., linear dynamical systems) using either EM or SGD, and how to use the fitted parameters to infer latent states and denoise the data. You can use the parameters for several other tasks as well. For example,
You can compute the filtering of the latent states using the
model.filterfunction.You can sample new states and observations from the fitted model and use them, for example, to forecast new observations.
You can study the system dynamics and their properties in
params.dynamics.
The next notebook shows how to do Bayesian inference of the parameters using Hamiltonian Monte Carlo.