What are State Space Models?
Contents
# meta-data does not work yet in VScode
# https://github.com/microsoft/vscode-jupyter/issues/1121
{
"tags": [
"hide-cell"
]
}
### Install necessary libraries
try:
import jax
except:
# For cuda version, see https://github.com/google/jax#installation
%pip install --upgrade "jax[cpu]"
import jax
try:
import distrax
except:
%pip install --upgrade distrax
import distrax
try:
import jsl
except:
%pip install git+https://github.com/probml/jsl
import jsl
try:
import rich
except:
%pip install rich
import rich
{
"tags": [
"hide-cell"
]
}
### Import standard libraries
import abc
from dataclasses import dataclass
import functools
import itertools
from typing import Any, Callable, NamedTuple, Optional, Union, Tuple
import matplotlib.pyplot as plt
import numpy as np
import jax
import jax.numpy as jnp
from jax import lax, vmap, jit, grad
from jax.scipy.special import logit
from jax.nn import softmax
from functools import partial
from jax.random import PRNGKey, split
import inspect
import inspect as py_inspect
import rich
from rich import inspect as r_inspect
from rich import print as r_print
def print_source(fname):
r_print(py_inspect.getsource(fname))
What are State Space Models?¶
A state space model or SSM is a partially observed Markov model, in which the hidden state, \(\hidden_t\), evolves over time according to a Markov process, possibly conditional on external inputs or controls \(\input_t\), and each hidden state generates some observations \(\obs_t\) at each time step. (In this book, we mostly focus on discrete time systems, although we consider the continuous-time case in XXX.) We get to see the observations, but not the hidden state. Our main goal is to infer the hidden state given the observations. However, we can also use the model to predict future observations, by first predicting future hidden states, and then predicting what observations they might generate. By using a hidden state \(\hidden_t\) to represent the past observations, \(\obs_{1:t-1}\), the model can have ``infinite’’ memory, unlike a standard Markov model.
Formally we can define an SSM as the following joint distribution:
where \(p(\hmmhid_t|\hmmhid_{t-1},\inputs_t)\) is the
transition model,
\(p(\hmmobs_t|\hmmhid_t, \inputs_t, \hmmobs_{t-1})\) is the
observation model,
and \(\inputs_{t}\) is an optional input or action.
See Figure %s
for an illustration of the corresponding graphical model.
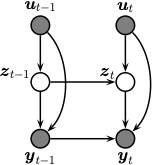
Illustration of an SSM as a graphical model.¶
We often consider a simpler setting in which the observations are conditionally independent of each other (rather than having Markovian dependencies) given the hidden state. In this case the joint simplifies to
Sometimes there are no external inputs, so the model further simplifies to the following unconditional generative model:
See Figure %s
for an illustration of the corresponding graphical model.
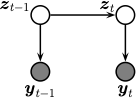
Illustration of a simplified SSM.¶
Linear Gaussian SSMs¶
Consider the state space model in () where we assume the observations are conditionally iid given the hidden states and inputs (i.e. there are no auto-regressive dependencies between the observables). We can rewrite this model as a stochastic nonlinear dynamical system (NLDS) by defining the distribution of the next hidden state as a deterministic function of the past state plus random process noise \(\vepsilon_t\)
where \(\vepsilon_t\) is drawn from the distribution such that the induced distribution on \(\hmmhid_t\) matches \(p(\hmmhid_t|\hmmhid_{t-1}, \inputs_t)\). Similarly we can rewrite the observation distributions as a deterministic function of the hidden state plus observation noise \(\veta_t\):
If we assume additive Gaussian noise, the model becomes
where \(\vepsilon_t \sim \gauss(\vzero,\vQ_t)\) and \(\veta_t \sim \gauss(\vzero,\vR_t)\). We will call these Gaussian SSMs.
If we additionally assume the transition function \(\ssmDynFn\) and the observation function \(\ssmObsFn\) are both linear, then we can rewrite the model as follows:
This is called a linear-Gaussian state space model (LG-SSM), or a linear dynamical system (LDS). We usually assume the parameters are independent of time, in which case the model is said to be time-invariant or homogeneous.
Example: tracking a 2d point¶
Consider an object moving in \(\real^2\). Let the state be the position and velocity of the object, $\(\vz_t =\begin{pmatrix} u_t & \dot{u}_t & v_t & \dot{v}_t \end{pmatrix}\)\(. (We use \)u\( and \)v$ for the two coordinates, to avoid confusion with the state and observation variables.) If we use Euler discretization, the dynamics become
where \(\vepsilon_t \sim \gauss(\vzero,\vQ)\) is the process noise.
Let us assume that the process noise is a white noise process added to the velocity components of the state, but not to the location. (This is known as a random accelerations model.) We can approximate the resulting process in discrete time by assuming \(\vQ = \diag(0, q, 0, q)\). (See [Sar13] p60 for a more accurate way to convert the continuous time process to discrete time.)
Now suppose that at each discrete time point we observe the location, corrupted by Gaussian noise. Thus the observation model becomes
where \(\veta_t \sim \gauss(\vzero,\vR)\) is the \keywordDef{observation noise}. We see that the observation matrix \(\ldsObs\) simply ``extracts’’ the relevant parts of the state vector.
Suppose we sample a trajectory and corresponding set of noisy observations from this model, \((\vz_{1:T}, \vy_{1:T}) \sim p(\vz,\vy|\vtheta)\). (We use diagonal observation noise, \(\vR = \diag(\sigma_1^2, \sigma_2^2)\).) The results are shown below.
key = jax.random.PRNGKey(314)
timesteps = 15
delta = 1.0
A = jnp.array([
[1, 0, delta, 0],
[0, 1, 0, delta],
[0, 0, 1, 0],
[0, 0, 0, 1]
])
C = jnp.array([
[1, 0, 0, 0],
[0, 1, 0, 0]
])
state_size, _ = A.shape
observation_size, _ = C.shape
Q = jnp.eye(state_size) * 0.001
R = jnp.eye(observation_size) * 1.0
# Prior parameter distribution
mu0 = jnp.array([8, 10, 1, 0]).astype(float)
Sigma0 = jnp.eye(state_size) * 1.0
from jsl.lds.kalman_filter import LDS, smooth, filter
lds = LDS(A, C, Q, R, mu0, Sigma0)
print(lds)
LDS(A=DeviceArray([[1., 0., 1., 0.],
[0., 1., 0., 1.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]], dtype=float32), C=DeviceArray([[1, 0, 0, 0],
[0, 1, 0, 0]], dtype=int32), Q=DeviceArray([[0.001, 0. , 0. , 0. ],
[0. , 0.001, 0. , 0. ],
[0. , 0. , 0.001, 0. ],
[0. , 0. , 0. , 0.001]], dtype=float32), R=DeviceArray([[1., 0.],
[0., 1.]], dtype=float32), mu=DeviceArray([ 8., 10., 1., 0.], dtype=float32), Sigma=DeviceArray([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]], dtype=float32), state_offset=None, obs_offset=None, nstates=4, nobs=2)
from jsl.demos.plot_utils import plot_ellipse
def plot_tracking_values(observed, filtered, cov_hist, signal_label, ax):
timesteps, _ = observed.shape
ax.plot(observed[:, 0], observed[:, 1], marker="o", linewidth=0,
markerfacecolor="none", markeredgewidth=2, markersize=8, label="observed", c="tab:green")
ax.plot(*filtered[:, :2].T, label=signal_label, c="tab:red", marker="x", linewidth=2)
for t in range(0, timesteps, 1):
covn = cov_hist[t][:2, :2]
plot_ellipse(covn, filtered[t, :2], ax, n_std=2.0, plot_center=False)
ax.axis("equal")
ax.legend()
z_hist, x_hist = lds.sample(key, timesteps)
fig_truth, axs = plt.subplots()
axs.plot(x_hist[:, 0], x_hist[:, 1],
marker="o", linewidth=0, markerfacecolor="none",
markeredgewidth=2, markersize=8,
label="observed", c="tab:green")
axs.plot(z_hist[:, 0], z_hist[:, 1],
linewidth=2, label="truth",
marker="s", markersize=8)
axs.legend()
axs.axis("equal")
(7.24486608505249, 23.857812213897706, 8.042076778411865, 11.636079120635987)
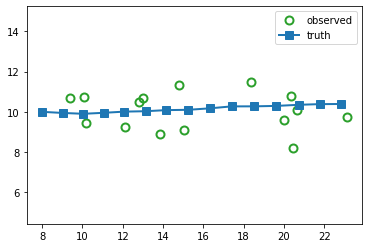
The main task is to infer the hidden states given the noisy observations, i.e., \(p(\vz|\vy,\vtheta)\). We discuss the topic of inference in Inferential goals.
Nonlinear Gaussian SSMs¶
In this section, we consider SSMs in which the dynamics and/or observation models are nonlinear, but the process noise and observation noise are Gaussian. That is,
where \(\vepsilon_t \sim \gauss(\vzero,\vQ_t)\) and \(\veta_t \sim \gauss(\vzero,\vR_t)\). This is a very widely used model class. We give some examples below.
Example: tracking a 1d pendulum¶
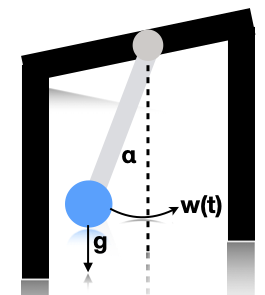
Illustration of a pendulum swinging. \(g\) is the force of gravity, \(w(t)\) is a random external force, and \(\alpha\) is the angle wrt the vertical. Based on [Sar13] fig 3.10.¶
Consider a simple pendulum of unit mass and length swinging from a fixed attachment, as in Illustration of a pendulum swinging. g is the force of gravity, w(t) is a random external force, and \alpha is the angle wrt the vertical. Based on Sarkka13 fig 3.10.. Such an object is in principle entirely deterministic in its behavior. However, in the real world, there are often unknown forces at work (e.g., air turbulence, friction). We will model these by a continuous time random Gaussian noise process \(w(t)\). This gives rise to the following differential equation:
We can write this as a nonlinear SSM by defining the state to be \(z_1(t) = \alpha(t)\) and \(z_2(t) = d\alpha(t)/dt\). Thus
If we discretize this step size \(\Delta\), we get the following formulation [Sar13] p74:
where \(\vq_{t-1} \sim \gauss(\vzero,\vQ)\) with
where \(q^c\) is the spectral density (continuous time variance) of the continuous-time noise process.
If we observe the angular position, we get the linear observation model
where \(h(\hmmhid_t) = z_{1,t}\) and \(r_t\) is the observation noise. If we only observe the horizontal position, we get the nonlinear observation model
where \(h(\hmmhid_t) = \sin(z_{1,t})\).
Inferential goals¶
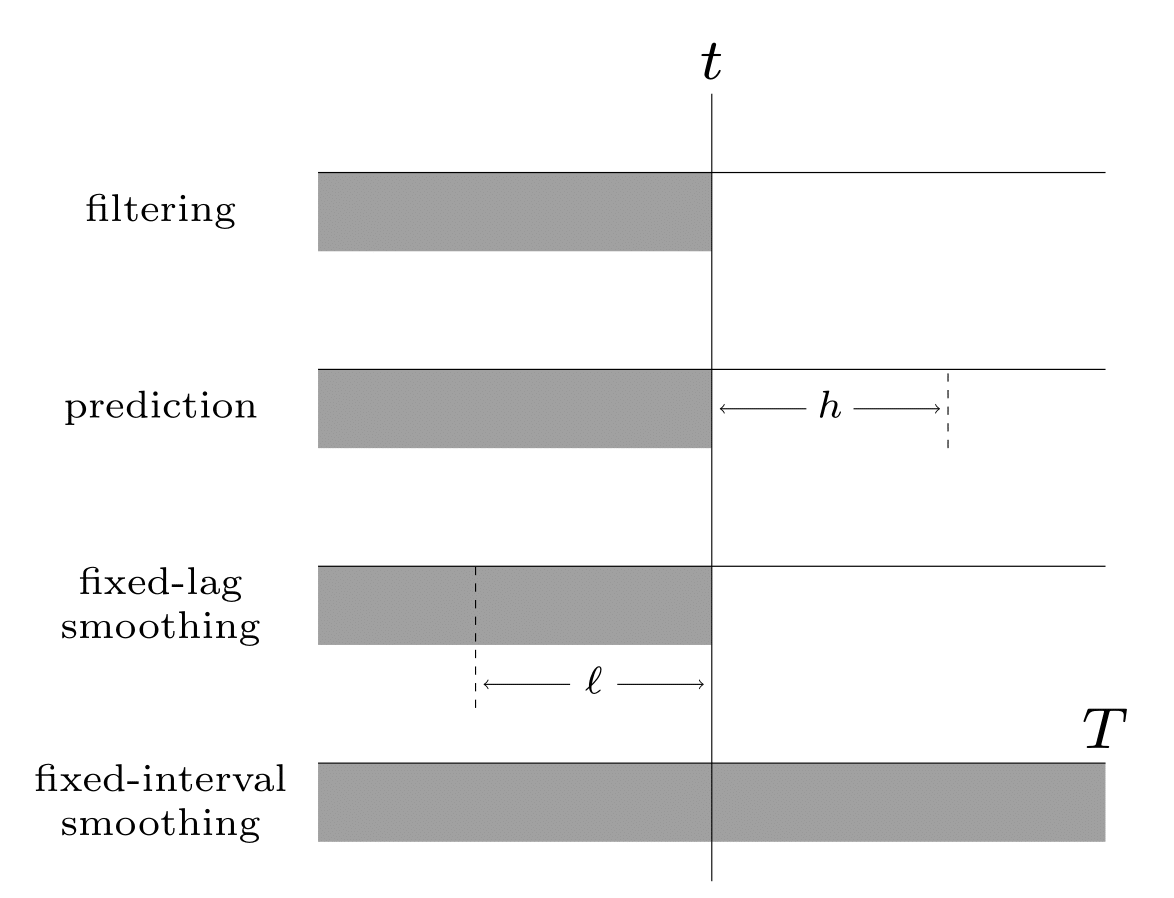
Illustration of the different kinds of inference in an SSM. The main kinds of inference for state-space models. The shaded region is the interval for which we have data. The arrow represents the time step at which we want to perform inference. \(t\) is the current time, \(T\) is the sequence length, \(\ell\) is the lag and \(h\) is the prediction horizon.¶
Given the sequence of observations, and a known model, one of the main tasks with SSMs to perform posterior inference, about the hidden states; this is also called state estimation. At each time step \(t\), there are multiple forms of posterior we may be interested in computing, including the following:
the filtering distribution \(p(\hmmhid_t|\hmmobs_{1:t})\)
the smoothing distribution \(p(\hmmhid_t|\hmmobs_{1:T})\) (note that this conditions on future data \(T>t\))
the fixed-lag smoothing distribution \(p(\hmmhid_{t-\ell}|\hmmobs_{1:t})\) (note that this infers \(\ell\) steps in the past given data up to the present).
We may also want to compute the predictive distribution \(h\) steps into the future:
where the hidden state predictive distribution is
See Illustration of the different kinds of inference in an SSM. The main kinds of inference for state-space models. The shaded region is the interval for which we have data. The arrow represents the time step at which we want to perform inference. t is the current time, T is the sequence length, \ell is the lag and h is the prediction horizon. for a summary of these distributions.
In addition to comuting posterior marginals, we may want to compute the most probable hidden sequence, i.e., the joint MAP estimate
or sample sequences from the posterior
Algorithms for all these task are discussed in the following chapters, since the details depend on the form of the SSM.
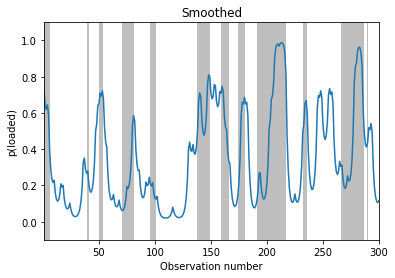
Example: inference in the casino HMM¶
We now illustrate filtering, smoothing and MAP decoding applied to the casino HMM from sec:casino.
# Call inference engine
filtered_dist, _, smoothed_dist, loglik = hmm.forward_backward(x_hist)
map_path = hmm.viterbi(x_hist)
/opt/anaconda3/lib/python3.8/site-packages/jax/_src/numpy/lax_numpy.py:5154: UserWarning: Explicitly requested dtype <class 'jax._src.numpy.lax_numpy.int64'> requested in astype is not available, and will be truncated to dtype int32. To enable more dtypes, set the jax_enable_x64 configuration option or the JAX_ENABLE_X64 shell environment variable. See https://github.com/google/jax#current-gotchas for more.
lax_internal._check_user_dtype_supported(dtype, "astype")
# Find the span of timesteps that the simulated systems turns to be in state 1
def find_dishonest_intervals(z_hist):
spans = []
x_init = 0
for t, _ in enumerate(z_hist[:-1]):
if z_hist[t + 1] == 0 and z_hist[t] == 1:
x_end = t
spans.append((x_init, x_end))
elif z_hist[t + 1] == 1 and z_hist[t] == 0:
x_init = t + 1
return spans
# Plot posterior
def plot_inference(inference_values, z_hist, ax, state=1, map_estimate=False):
n_samples = len(inference_values)
xspan = np.arange(1, n_samples + 1)
spans = find_dishonest_intervals(z_hist)
if map_estimate:
ax.step(xspan, inference_values, where="post")
else:
ax.plot(xspan, inference_values[:, state])
for span in spans:
ax.axvspan(*span, alpha=0.5, facecolor="tab:gray", edgecolor="none")
ax.set_xlim(1, n_samples)
# ax.set_ylim(0, 1)
ax.set_ylim(-0.1, 1.1)
ax.set_xlabel("Observation number")
# Filtering
fig, ax = plt.subplots()
plot_inference(filtered_dist, z_hist, ax)
ax.set_ylabel("p(loaded)")
ax.set_title("Filtered")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-17-a3a9c11b46bd> in <module>
1 # Filtering
2 fig, ax = plt.subplots()
----> 3 plot_inference(filtered_dist, z_hist, ax)
4 ax.set_ylabel("p(loaded)")
5 ax.set_title("Filtered")
<ipython-input-16-9c8ddad3f57c> in plot_inference(inference_values, z_hist, ax, state, map_estimate)
3 n_samples = len(inference_values)
4 xspan = np.arange(1, n_samples + 1)
----> 5 spans = find_dishonest_intervals(z_hist)
6 if map_estimate:
7 ax.step(xspan, inference_values, where="post")
<ipython-input-15-4606c615e17a> in find_dishonest_intervals(z_hist)
4 x_init = 0
5 for t, _ in enumerate(z_hist[:-1]):
----> 6 if z_hist[t + 1] == 0 and z_hist[t] == 1:
7 x_end = t
8 spans.append((x_init, x_end))
/opt/anaconda3/lib/python3.8/functools.py in _method(cls_or_self, *args, **keywords)
397 def _method(cls_or_self, /, *args, **keywords):
398 keywords = {**self.keywords, **keywords}
--> 399 return self.func(cls_or_self, *self.args, *args, **keywords)
400 _method.__isabstractmethod__ = self.__isabstractmethod__
401 _method._partialmethod = self
/opt/anaconda3/lib/python3.8/site-packages/jax/_src/device_array.py in _forward_method(attrname, self, fun, *args)
39
40 def _forward_method(attrname, self, fun, *args):
---> 41 return fun(getattr(self, attrname), *args)
42 _forward_to_value = partial(_forward_method, "_value")
43
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()

# Smoothing
fig, ax = plt.subplots()
plot_inference(smoothed_dist, z_hist, ax)
ax.set_ylabel("p(loaded)")
ax.set_title("Smoothed")
Text(0.5, 1.0, 'Smoothed')
# MAP estimation
fig, ax = plt.subplots()
plot_inference(map_path, z_hist, ax, map_estimate=True)
ax.set_ylabel("MAP state")
ax.set_title("Viterbi")
# TODO: posterior samples
Example: inference in the tracking SSM¶
We now illustrate filtering, smoothing and MAP decoding applied to the 2d tracking HMM from Example: tracking a 2d point.