Hidden Markov Models
Contents
Hidden Markov Models¶
In this section, we discuss the hidden Markov model or HMM, which is a state space model in which the hidden states are discrete, so \(\hidden_t \in \{1,\ldots, \nstates\}\). The observations may be discrete, \(\obs_t \in \{1,\ldots, \nsymbols\}\), or continuous, \(\obs_t \in \real^\nstates\), or some combination, as we illustrate below. More details can be found in e.g., [CMR05, Fra08, Rab89]. For an interactive introduction, see https://nipunbatra.github.io/hmm/.
{
"tags": [
"hide-cell"
]
}
### Import standard libraries
import abc
from dataclasses import dataclass
import functools
from functools import partial
import itertools
import matplotlib.pyplot as plt
import numpy as np
from typing import Any, Callable, NamedTuple, Optional, Union, Tuple
import jax
import jax.numpy as jnp
from jax import lax, vmap, jit, grad
#from jax.scipy.special import logit
#from jax.nn import softmax
import jax.random as jr
import distrax
import optax
import jsl
import ssm_jax
import inspect
import inspect as py_inspect
import rich
from rich import inspect as r_inspect
from rich import print as r_print
def print_source(fname):
r_print(py_inspect.getsource(fname))
Example: Casino HMM¶
To illustrate HMMs with categorical observation model, we consider the “Ocassionally dishonest casino” model from [DEKM98]. There are 2 hidden states, representing whether the dice being used in the casino is fair or loaded. Each state defines a distribution over the 6 possible observations.
The transition model is denoted by
Here the \(i\)’th row of \(\hmmTrans\) corresponds to the outgoing distribution from state \(i\). This is a row stochastic matrix, meaning each row sums to one. We can visualize the non-zero entries in the transition matrix by creating a state transition diagram, as shown in Fig. 3.
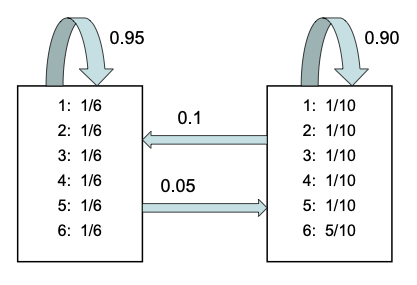
Fig. 3 Illustration of the casino HMM.¶
The observation model \(p(\obs_t|\hidden_t=j)\) has the form
This is represented by the histograms associated with each state in Fig. 3.
Finally, the initial state distribution is denoted by
Collectively we denote all the parameters by \(\params=(\hmmTrans, \hmmObs, \hmmInit)\).
Now let us implement this model in code.
# state transition matrix
A = np.array([
[0.95, 0.05],
[0.10, 0.90]
])
# observation matrix
B = np.array([
[1/6, 1/6, 1/6, 1/6, 1/6, 1/6], # fair die
[1/10, 1/10, 1/10, 1/10, 1/10, 5/10] # loaded die
])
pi = np.array([0.5, 0.5])
(nstates, nobs) = np.shape(B)
import distrax
from distrax import HMM
hmm = HMM(trans_dist=distrax.Categorical(probs=A),
init_dist=distrax.Categorical(probs=pi),
obs_dist=distrax.Categorical(probs=B))
print(hmm)
WARNING:absl:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
<distrax._src.utils.hmm.HMM object at 0x7fbca906ad60>
Let’s sample from the model. We will generate a sequence of latent states, \(\hidden_{1:T}\), which we then convert to a sequence of observations, \(\obs_{1:T}\).
seed = 314
n_samples = 300
z_hist, x_hist = hmm.sample(seed=jr.PRNGKey(seed), seq_len=n_samples)
z_hist_str = "".join((np.array(z_hist) + 1).astype(str))[:60]
x_hist_str = "".join((np.array(x_hist) + 1).astype(str))[:60]
print("Printing sample observed/latent...")
print(f"x: {x_hist_str}")
print(f"z: {z_hist_str}")
Printing sample observed/latent...
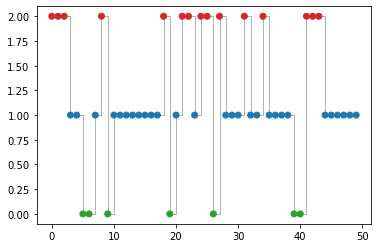
x: 633665342652353616444236412331351246651613325161656366246242
z: 222222211111111111111111111111111111111222111111112222211111
Below is the source code for the sampling algorithm.
print_source(hmm.sample)
def sample(self, *, seed: chex.PRNGKey, seq_len: chex.Array) -> Tuple: """Sample from this HMM. Samples an observation of given length according to this Hidden Markov Model and gives the sequence of the hidden states as well as the observation. Args: seed: Random key of shape (2,) and dtype uint32. seq_len: The length of the observation sequence. Returns: Tuple of hidden state sequence, and observation sequence. """ rng_key, rng_init = jax.random.split(seed) initial_state = self._init_dist.sample(seed=rng_init) def draw_state(prev_state, key): state = self._trans_dist.sample(seed=key) return state, state rng_state, rng_obs = jax.random.split(rng_key) keys = jax.random.split(rng_state, seq_len - 1) _, states = jax.lax.scan(draw_state, initial_state, keys) states = jnp.append(initial_state, states) def draw_obs(state, key): return self._obs_dist.sample(seed=key) keys = jax.random.split(rng_obs, seq_len) obs_seq = jax.vmap(draw_obs, in_axes=(0, 0))(states, keys) return states, obs_seq
Let us check correctness by computing empirical pairwise statistics
We will compute the number of i->j latent state transitions, and check that it is close to the true A[i,j] transition probabilites.
import collections
def compute_counts(state_seq, nstates):
wseq = np.array(state_seq)
word_pairs = [pair for pair in zip(wseq[:-1], wseq[1:])]
counter_pairs = collections.Counter(word_pairs)
counts = np.zeros((nstates, nstates))
for (k,v) in counter_pairs.items():
counts[k[0], k[1]] = v
return counts
def normalize(u, axis=0, eps=1e-15):
u = jnp.where(u == 0, 0, jnp.where(u < eps, eps, u))
c = u.sum(axis=axis)
c = jnp.where(c == 0, 1, c)
return u / c, c
def normalize_counts(counts):
ncounts = vmap(lambda v: normalize(v)[0], in_axes=0)(counts)
return ncounts
init_dist = jnp.array([1.0, 0.0])
trans_mat = jnp.array([[0.7, 0.3], [0.5, 0.5]])
obs_mat = jnp.eye(2)
hmm = HMM(trans_dist=distrax.Categorical(probs=trans_mat),
init_dist=distrax.Categorical(probs=init_dist),
obs_dist=distrax.Categorical(probs=obs_mat))
rng_key = jax.random.PRNGKey(0)
seq_len = 500
state_seq, _ = hmm.sample(seed=PRNGKey(seed), seq_len=seq_len)
counts = compute_counts(state_seq, nstates=2)
print(counts)
trans_mat_empirical = normalize_counts(counts)
print(trans_mat_empirical)
assert jnp.allclose(trans_mat, trans_mat_empirical, atol=1e-1)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-6-f054683fcd82> in <module>
30 rng_key = jax.random.PRNGKey(0)
31 seq_len = 500
---> 32 state_seq, _ = hmm.sample(seed=PRNGKey(seed), seq_len=seq_len)
33
34 counts = compute_counts(state_seq, nstates=2)
NameError: name 'PRNGKey' is not defined
Our primary goal will be to infer the latent state from the observations, so we can detect if the casino is being dishonest or not. This will affect how we choose to gamble our money. We discuss various ways to perform this inference below.
Example: Lillypad HMM¶
If \(\obs_t\) is continuous, it is common to use a Gaussian observation model:
This is sometimes called a Gaussian HMM.
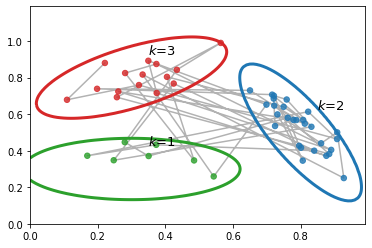
As a simple example, suppose we have an HMM with 3 hidden states, each of which generates a 2d Gaussian. We can represent these Gaussian distributions are 2d ellipses, as we show below. We call these ``lilly pads’’, because of their shape. We can imagine a frog hopping from one lilly pad to another. (This analogy is due to the late Sam Roweis.) The frog will stay on a pad for a while (corresponding to remaining in the same discrete state \(\hidden_t\)), and then jump to a new pad (corresponding to a transition to a new state). The data we see are just the 2d points (e.g., water droplets) coming from near the pad that the frog is currently on. Thus this model is like a Gaussian mixture model, in that it generates clusters of observations, except now there is temporal correlation between the data points.
Let us now illustrate this model in code.
# Let us create the model
initial_probs = jnp.array([0.3, 0.2, 0.5])
# transition matrix
A = jnp.array([
[0.3, 0.4, 0.3],
[0.1, 0.6, 0.3],
[0.2, 0.3, 0.5]
])
# Observation model
mu_collection = jnp.array([
[0.3, 0.3],
[0.8, 0.5],
[0.3, 0.8]
])
S1 = jnp.array([[1.1, 0], [0, 0.3]])
S2 = jnp.array([[0.3, -0.5], [-0.5, 1.3]])
S3 = jnp.array([[0.8, 0.4], [0.4, 0.5]])
cov_collection = jnp.array([S1, S2, S3]) / 60
import tensorflow_probability as tfp
if False:
hmm = HMM(trans_dist=distrax.Categorical(probs=A),
init_dist=distrax.Categorical(probs=initial_probs),
obs_dist=distrax.MultivariateNormalFullCovariance(
loc=mu_collection, covariance_matrix=cov_collection))
else:
hmm = HMM(trans_dist=distrax.Categorical(probs=A),
init_dist=distrax.Categorical(probs=initial_probs),
obs_dist=distrax.as_distribution(
tfp.substrates.jax.distributions.MultivariateNormalFullCovariance(loc=mu_collection,
covariance_matrix=cov_collection)))
print(hmm)
<distrax._src.utils.hmm.HMM object at 0x7fd658f7b7f0>
n_samples, seed = 50, 10
samples_state, samples_obs = hmm.sample(seed=PRNGKey(seed), seq_len=n_samples)
print(samples_state.shape)
print(samples_obs.shape)
(50,)
(50, 2)
# Let's plot the observed data in 2d
xmin, xmax = 0, 1
ymin, ymax = 0, 1.2
colors = ["tab:green", "tab:blue", "tab:red"]
def plot_2dhmm(hmm, samples_obs, samples_state, colors, ax, xmin, xmax, ymin, ymax, step=1e-2):
obs_dist = hmm.obs_dist
color_sample = [colors[i] for i in samples_state]
xs = jnp.arange(xmin, xmax, step)
ys = jnp.arange(ymin, ymax, step)
v_prob = vmap(lambda x, y: obs_dist.prob(jnp.array([x, y])), in_axes=(None, 0))
z = vmap(v_prob, in_axes=(0, None))(xs, ys)
grid = np.mgrid[xmin:xmax:step, ymin:ymax:step]
for k, color in enumerate(colors):
ax.contour(*grid, z[:, :, k], levels=[1], colors=color, linewidths=3)
ax.text(*(obs_dist.mean()[k] + 0.13), f"$k$={k + 1}", fontsize=13, horizontalalignment="right")
ax.plot(*samples_obs.T, c="black", alpha=0.3, zorder=1)
ax.scatter(*samples_obs.T, c=color_sample, s=30, zorder=2, alpha=0.8)
return ax, color_sample
fig, ax = plt.subplots()
_, color_sample = plot_2dhmm(hmm, samples_obs, samples_state, colors, ax, xmin, xmax, ymin, ymax)
# Let's plot the hidden state sequence
fig, ax = plt.subplots()
ax.step(range(n_samples), samples_state, where="post", c="black", linewidth=1, alpha=0.3)
ax.scatter(range(n_samples), samples_state, c=color_sample, zorder=3)
<matplotlib.collections.PathCollection at 0x7fd5e174b460>